The ETL process has been designed specifically for the purpose of transferring data from its source database into a data warehouse. However, the challenges and complexities of ETL can make it hard to implement successfully for all of your enterprise data. For this reason, Amazon has introduced AWS Glue. You can learn more about the Amazon web services with the AWS Training and Certification.
In this article, the pointers that we are going to cover are as follows:
- What is AWS Glue?
- When should I use AWS Glue?
- AWS Glue Benefits
- The AWS Glue Concepts
- AWS Glue Terminology
- How does AWS Glue work?
So let us begin with our first topic.
What is AWS Glue?
- AWS Glue is a fully managed ETL service. This service makes it simple and cost-effective to categorize your data, clean it, enrich it, and move it swiftly and reliably between various data stores.
- It comprises of components such as a central metadata repository known as the AWS Glue Data Catalog, an ETL engine that automatically generates Python or Scala code, and a flexible scheduler that handles dependency resolution, job monitoring, and retries.
- AWS Glue is serverless, this means that there’s no infrastructure to set up or manage.
When Should I Use AWS Glue?
1. To build a data warehouse to organize, cleanse, validate, and format data.
- You can transform as well as move AWS Cloud data into your data store.
- You can also load data from disparate sources into your data warehouse for regular reporting and analysis.
- By storing it in a data warehouse, you integrate information from different parts of your business and provide a common source of data for decision making.
2. When you run serverless queries against your Amazon S3 data lake.
- AWS Glue can catalog your Amazon Simple Storage Service (Amazon S3) data, making it available for querying with Amazon Athena and Amazon Redshift Spectrum.
- With crawlers, your metadata stays in synchronization with the underlying data. Athena and Redshift Spectrum can directly query your Amazon S3 data lake with the help of the AWS Glue Data Catalog.
- With AWS Glue, you access as well as analyze data through one unified interface without loading it into multiple data silos.
3. When you want to create event-driven ETL pipelines
- You can run your ETL jobs as soon as new data becomes available in Amazon S3 by invoking your AWS Glue ETL jobs from an AWS Lambda function.
- You can also register this new dataset in the AWS Glue Data Catalog considering it as part of your ETL jobs.
4. To understand your data assets.
- You can store your data using various AWS services and still maintain a unified view of your data using the AWS Glue Data Catalog.
- View the Data Catalog to quickly search and discover the datasets that you own, and maintain the relevant metadata in one central repository.
- The Data Catalog also serves as a drop-in replacement for your external Apache Hive Metastore.
AWS Glue Benefits
1. Less hassle
 AWS Glue is integrated across a very wide range of AWS services. AWS Glue natively supports data stored in Amazon Aurora and all other Amazon RDS engines, Amazon Redshift, and Amazon S3, along with common database engines and databases in your Virtual Private Cloud (Amazon VPC) running on Amazon EC2.
AWS Glue is integrated across a very wide range of AWS services. AWS Glue natively supports data stored in Amazon Aurora and all other Amazon RDS engines, Amazon Redshift, and Amazon S3, along with common database engines and databases in your Virtual Private Cloud (Amazon VPC) running on Amazon EC2.
2. Cost-effective
 AWS Glue is serverless. There is no infrastructure to provision or manage. AWS Glue handles provisioning, configuration, and scaling of the resources required to run your ETL jobs on a fully managed, scale-out Apache Spark environment. You pay only for the resources that you use while your jobs are running.
AWS Glue is serverless. There is no infrastructure to provision or manage. AWS Glue handles provisioning, configuration, and scaling of the resources required to run your ETL jobs on a fully managed, scale-out Apache Spark environment. You pay only for the resources that you use while your jobs are running.
3. More power
 AWS Glue automates a significant amount of effort in building, maintaining, and running ETL jobs. It crawls your data sources, identifies data formats as well as suggests schemas and transformations. AWS Glue automatically generates the code to execute your data transformations and loading processes.
AWS Glue automates a significant amount of effort in building, maintaining, and running ETL jobs. It crawls your data sources, identifies data formats as well as suggests schemas and transformations. AWS Glue automatically generates the code to execute your data transformations and loading processes.
AWS Glue Concepts
You define jobs in AWS Glue to accomplish the work that’s required to extract, transform, and load (ETL) data from a data source to a data target. You typically perform the following actions:

- Firstly, you define a crawler to populate your AWS Glue Data Catalog with metadata table definitions. You point your crawler at a data store, and the crawler creates table definitions in the Data Catalog. In addition to table definitions, the Data Catalog contains other metadata that is required to define ETL jobs. You use this metadata when you define a job to transform your data.
- AWS Glue can generate a script to transform your data or you can also provide the script in the AWS Glue console or API.
- You can run your job on-demand, or you can set it up to start when a specified trigger occurs. The trigger can be a time-based schedule or an event.
- When your job runs, a script extracts data from your data source, transforms the data, and loads it to your data target. This script runs in an Apache Spark environment in AWS Glue.
You can learn more about AWS and its services from the AWS Cloud Course.
AWS Glue Terminology
How does AWS Glue work?
Here I am going to demonstrate an example where I will create a transformation script with Python and Spark. I will also cover some basic Glue concepts such as crawler, database, table, and job.
Create a data source for AWS Glue:
Glue can read data from a database or S3 bucket. For example, I have created an S3 bucket called glue-bucket-edureka. Create two folders from S3 console and name them read and write. Now create a text file with the following data and upload it to the read folder of S3 bucket.
rank,movie_title,year,rating
1,The Shawshank Redemption,1994,9.2
2,The Godfather,1972,9.2
3,The Godfather: Part II,1974,9.0
4,The Dark Knight,2008,9.0
5,12 Angry Men,1957,8.9
6,Schindler’s List,1993,8.9
7,The Lord of the Rings: The Return of the King,2003,8.9
8,Pulp Fiction,1994,8.9
9,The Lord of the Rings: The Fellowship of the Ring,2001,8.8
10,Fight Club,1999,8.8Crawl the data source to the data catalog:
In this step, we will create a crawler. The crawler will catalog all files in the specified S3 bucket and prefix. All the files should have the same schema. In Glue crawler terminology the file format is known as a classifier. The crawler identifies the most common classifiers automatically including CSV, json and parquet. Our sample file is in the CSV format and will be recognized automatically.
- In the left panel of the Glue management console click Crawlers.
- Click the blue Add crawler button.
- Give the crawler a name such as glue-demo-edureka-crawler.
- In Add a data store menu choose S3 and select the bucket you created. Drill down to select the read folder.
- In Choose an IAM role create new. Name the role to for example glue-demo-edureka-iam-role.
- In Configure the crawler’s output add a database called glue-demo-edureka-db.
When you are back in the list of all crawlers, tick the crawler that you created. Click Run crawler.
3. The crawled metadata in Glue tables:
Once the data has been crawled, the crawler creates a metadata table from it. You find the results from the Tables section of the Glue console. The database that you created during the crawler setup is just an arbitrary way of grouping the tables. Glue tables don’t contain the data but only the instructions on how to access the data.
4. AWS Glue jobs for data transformations:
From the Glue console left panel go to Jobs and click blue Add job button. Follow these instructions to create the Glue job:
- Name the job as glue-demo-edureka-job.
- Choose the same IAM role that you created for the crawler. It can read and write to the S3 bucket.
- Type: Spark.
- Glue version: Spark 2.4, Python 3.
- This job runs: A new script to be authored by you.
- Security configuration, script libraries, and job parameters
- Maximum capacity: 2. This is the minimum and costs about 0.15$ per run.
- Job timeout: 10. Prevents the job to run longer than expected.
- Click Next and then Save job and edit the script.
5. Editing the Glue script to transform the data with Python and Spark:
Copy the following code to your Glue script editor Remember to change the bucket name for the s3_write_path variable. Save the code in the editor and click Run job.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 | ############################################ IMPORT LIBRARIES AND SET VARIABLES##########################################Import python modulesfrom datetime import datetime#Import pyspark modulesfrom pyspark.context import SparkContextimport pyspark.sql.functions as f#Import glue modulesfrom awsglue.utils import getResolvedOptionsfrom awsglue.context import GlueContextfrom awsglue.dynamicframe import DynamicFramefrom awsglue.job import Job#Initialize contexts and sessionspark_context = SparkContext.getOrCreate()glue_context = GlueContext(spark_context)session = glue_context.spark_session#Parametersglue_db = "glue-demo-edureka-db"glue_tbl = "read"s3_write_path = "s3://glue-demo-bucket-edureka/write"############################################ EXTRACT (READ DATA)##########################################Log starting timedt_start = datetime.now().strftime("%Y-%m-%d %H:%M:%S")print("Start time:", dt_start)#Read movie data to Glue dynamic framedynamic_frame_read = glue_context.create_dynamic_frame.from_catalog(database = glue_db, table_name = glue_tbl)#Convert dynamic frame to data frame to use standard pyspark functionsdata_frame = dynamic_frame_read.toDF()############################################ TRANSFORM (MODIFY DATA)##########################################Create a decade column from yeardecade_col = f.floor(data_frame["year"]/10)*10data_frame = data_frame.withColumn("decade", decade_col)#Group by decade: Count movies, get average ratingdata_frame_aggregated = data_frame.groupby("decade").agg(f.count(f.col("movie_title")).alias('movie_count'),f.mean(f.col("rating")).alias('rating_mean'),)#Sort by the number of movies per the decadedata_frame_aggregated = data_frame_aggregated.orderBy(f.desc("movie_count"))#Print result table#Note: Show function is an action. Actions force the execution of the data frame plan.#With big data the slowdown would be significant without cacching.data_frame_aggregated.show(10)############################################ LOAD (WRITE DATA)##########################################Create just 1 partition, because there is so little datadata_frame_aggregated = data_frame_aggregated.repartition(1)#Convert back to dynamic framedynamic_frame_write = DynamicFrame.fromDF(data_frame_aggregated, glue_context, "dynamic_frame_write")#Write data back to S3glue_context.write_dynamic_frame.from_options(frame = dynamic_frame_write,connection_type = "s3",connection_options = {"path": s3_write_path,#Here you could create S3 prefixes according to a values in specified columns#"partitionKeys": ["decade"]},format = "csv")#Log end timedt_end = datetime.now().strftime("%Y-%m-%d %H:%M:%S")print("Start time:", dt_end) |
The detailed explanations are commented in the code. Here is the high-level description:
- Read the movie data from S3
- Get movie count and rating average for each decade
- Write aggregated data back to S3
The execution time with 2 Data Processing Units (DPU) was around 40 seconds. A relatively long duration is explained by the start-up overhead.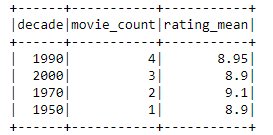
The data transformation script creates summarized movie data. For example, 2000 decade has 3 movies in IMDB top 10 with average rating 8.9. You can download the result file from the write folder of your S3 bucket. Another way to investigate the job would be to take a look at the CloudWatch logs.
The data is stored back to S3 as a CSV in the “write” prefix. The number of partitions equals the number of the output files. You can understand better about S3 and its concepts from the AWS Solution Architect Certification.
